
击败Meta登榜首:推理增强的文档排序模型ReasonRank来了
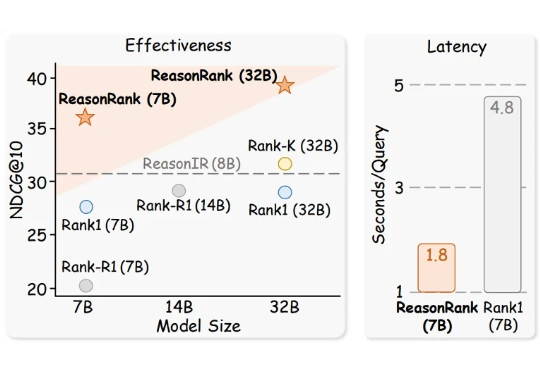
击败Meta登榜首:推理增强的文档排序模型ReasonRank来了推理大模型(Large Reasoning Model)极大的促进了自然语言处理领域的发展,而信息检索领域的核心问题之一是文档排序,如何利用强大的推理大模型通过主动推理来判断文档的相关性,进而再对文档进行排序是一个值得探索的方向。
来自主题: AI技术研报
6714 点击 2025-08-21 16:08
推理大模型(Large Reasoning Model)极大的促进了自然语言处理领域的发展,而信息检索领域的核心问题之一是文档排序,如何利用强大的推理大模型通过主动推理来判断文档的相关性,进而再对文档进行排序是一个值得探索的方向。
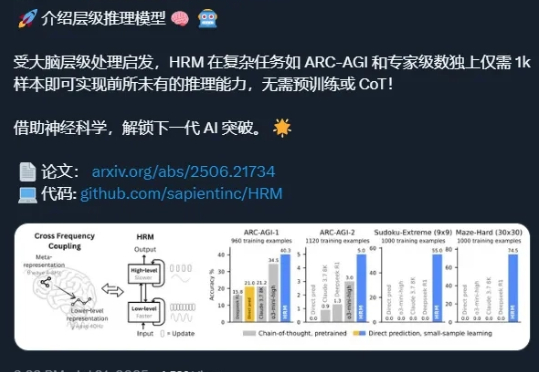
还记得分层推理模型(Hierarchical Reasoning Model,HRM)吗? 这项工作于 6 月份发布,当时引起了不小的轰动——X/Twitter 上的相关讨论获得了超过 400 万的浏览量和数万个点赞,剖析这项工作的 YouTube 视频观看量也超过了 47.5 万次。
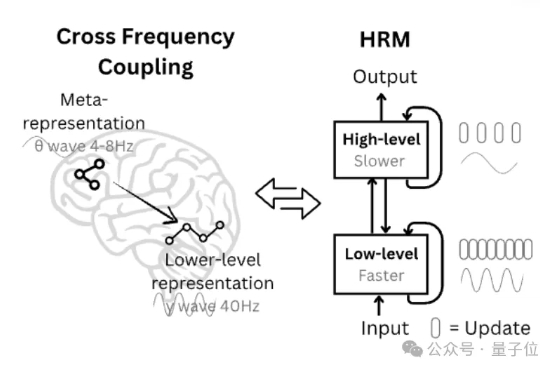
27M小模型超越o3-mini-high和DeepSeek-R1!推理还不靠思维链。 开发者是那位拒绝了马斯克、还要挑战Transformer的00后清华校友,Sapient Intelligence的创始人王冠。
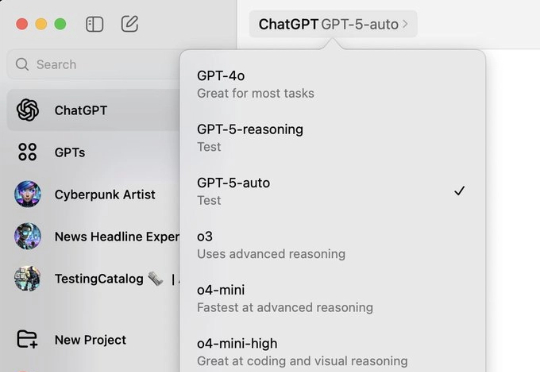
赢了的才是「GPT-5」。 GPT-5 迟迟未现身,网友们开始制作各种梗图「吐槽」其实,这几天关于 GPT-5 的传言就没消停。先是有网友在 macOS ChatGPT 应用中发现了 GPT-5-Auto 和 GPT-5-Reasoning 模型的踪迹:
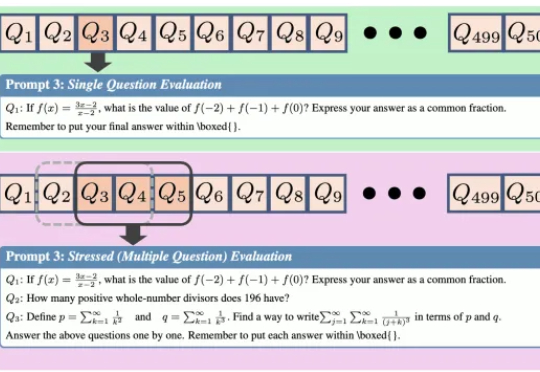
给AI一场压力测试,结果性能暴跌近30%。 来自上海人工智能实验室、清华大学和中国人民大学的研究团队设计了一个全新的“压力测试”框架——REST (Reasoning Evaluation through Simultaneous Testing)。
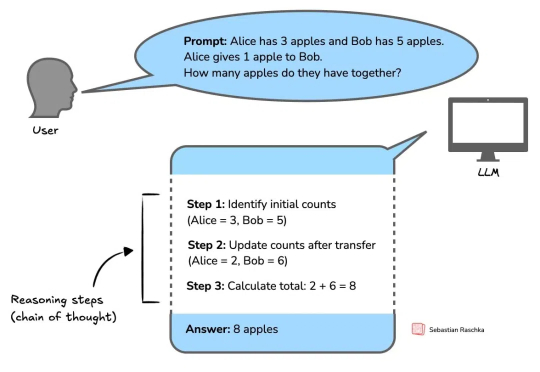
推理模型发展正盛,著名 AI 技术博主 Sebastian Raschka 也正在写一本关于推理模型工作方式的新书《Reasoning From Scratch》。

近年来,大模型(Large Language Models, LLMs)在数学、编程等复杂任务上取得突破,OpenAI-o1、DeepSeek-R1 等推理大模型(Reasoning Large Language Models,RLLMs)表现尤为亮眼。但它们为何如此强大呢?
当前搜索AI市场面临着一个显著的断层:Perplexity的Sonar Reasoning Pro和OpenAI的GPT-4o Search Preview等专有解决方案与开源替代品之间存在巨大差距。这些封闭式系统虽然表现优异,但却限制了透明度、创新和创业自由。作为一名正在开发Agent产品的工程师,你是否曾经渴望拥有一个功能强大且完全开放的搜索框架?
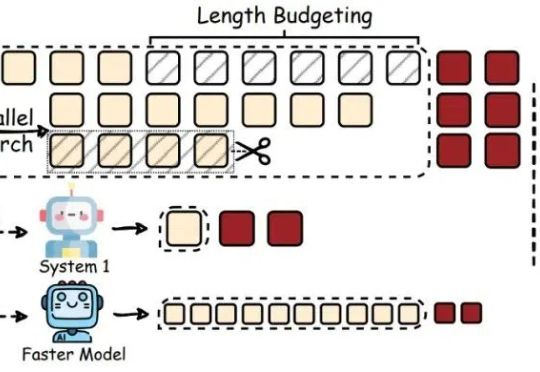
最近,像 OpenAI o1/o3、DeepSeek-R1 这样的大型推理模型(Large Reasoning Models,LRMs)通过加长「思考链」(Chain-of-Thought,CoT)在推理任务上表现惊艳。
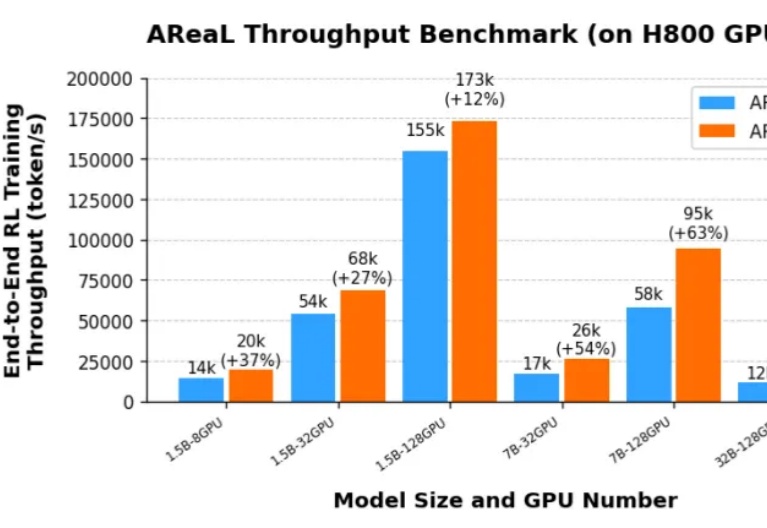
由于 DeepSeek R1 和 OpenAI o1 等推理模型(LRM,Large Reasoning Model)带来了新的 post-training scaling law,强化学习(RL,Reinforcement Learning)成为了大语言模型能力提升的新引擎。然而,针对大语言模型的大规模强化学习训练门槛一直很高: